分治算法大题
0、考察重点
题1,第二章的分治
关键词
1、分治过程(初始状态,第1趟状态,第n躺状态)
2、分治的算法分析,分析时间复杂度(数学推理/图示)
注:
分析时间复杂度的两种方法:
- 数学推理:迭代法、换元迭代、主定理
- 图示:递归树
注:该题可忽略,题目场景不常规。归并排序的分治思想需好好掌握。可见题9归并排序分治常规题。
1、假设你是一名软件工程师,正在开发一款应用,该应用需要处理和排序大量的用户数据。
这些数据是以一个“山脉数组”的形式给出的。山脉数组是一个先递增后递减的数组,
例如 [1, 3, 5, 7, 6, 4, 2]。你的任务是使用分治算法,先找到数组中的最大值(山顶),
然后对数组的两部分(山脉的两侧)分别进行合并排序。
a.描述找到山脉数组中最大值的分治过程,包括初始状态,第1趟状态,和第n趟状态。
b.描述对山脉数组两侧进行合并排序的分治过程。
c.分析整个算法(包括查找最大值和排序两侧)的时间复杂度。
考察知识点:二分查找、归并排序
解答:
a.分治过程
初始状态:
给定一个山脉数组,例如[1,3,5,7,6,4,2],其中数组先递增后递减。
第1趟状态
•使用二分查找法来找到最大值。
•首先,找到数组的中间元素(例如,7)。
•然后,比较中间元素与其相邻的元素,以判断最大值是在左侧递增部分还是右侧递减部分。
第n趟状态
•重复上述过程,每次都将搜索范围缩小一半,直到找到最大值。
b.对山脉数组两侧进行合并排序的分治过程。
左侧数组(递增部分)
1.分解:将数组分成两个子数组。
2.解决:递归地对这两个子数组进行归并排序。
3.合并:合并两个已排序的子数组。
右侧数组(递減部分)
1. 分解:同样将数组分成两个子数组。
2. 解决:递归地对这两个子数组进行归并排序。
3. 合并:合并两个已排序的子数组,但由于原始数组是递减的,需要在合并时逆序放置元素。
c.时间复杂度
查找最大值的时间复杂度
•由于使用二分查找,时间复杂度为O(logn),其中、n是数组的长度。
对两侧数组进行排序的时间复杂度
•归并排序的时间复杂度为O(nlogn)。
•由于山脉数组被分为两部分,每部分的排序也是O(nlogn)。
•但由于这两部分排序是连续的而不是并行的,
总的时间复杂度仍然是O(nlogn)。
•注意,虽然我们进行了两次归并排序(数组的两侧),
但它们是对原始数组的不同部分进行的,因此总体的排序步骤并没有增加。
2、
(1)若待排序元素存放于l数组中,且Swap(i,j)函数的作用为交换下标为i和j的两个元素l[i]和l[j]的值。
请写出快速排序算法的C语言程序,包含以下两个函数:
int Partition(int left, int right)
void QuickSort(int left, int right)
(2)对初始数据(5,8,4,6,3,7,1)执行快速排序,每次都选择左边第一个元素作为主元,
请给出每一趟分划操作的结果。并用[]标识子序列的边界。
(3)若待排序数据的规模为n,快速排序算法最好、最坏情况什么时候发生?
考察知识点:快速排序
解答:
(1)
int Partition(int left, int right)
{
int pivot = l[left]; // 选择最左侧的元素作为基准
int i = left; // 从left开始,而不是left-1
for (int j = left + 1; j <= right; j++)
{
if (l[j] < pivot)
{
i++;
Swap(i, j);
}
}
Swap(i, left); // 将pivot放到它的最终位置
return i; // 返回pivot的位置
}
// 快速排序(重载函数)
void QuickSort(int left, int right)
{
if (left < right)
{
int pi = Partition(left, right);
QuickSort(left, pi - 1);
QuickSort(pi + 1, right);
}
}
(2)
第一趟结果:[1,4,3],5,[8,7,6]
第二趟结果:[1],[4,3],5,[7,6],[8]
第三趟结果:[1],[3,4],5,[6,7],[8]
(3)
快速排序算法在最好、平均情况下的时间复杂度为O(nlogn),在最坏情况下的时间复杂度是O(n^2)。
每次分划操作后,若左、右两个子序列的长度基本相等,则快速排序效率最高,为最好情况。
原始序列正向有序或反向有序时,每次划分操作所产生的两个子序列,
其中之一为空序列,则快速排序效率最低,为最坏情况。
时间复杂度数学推导:

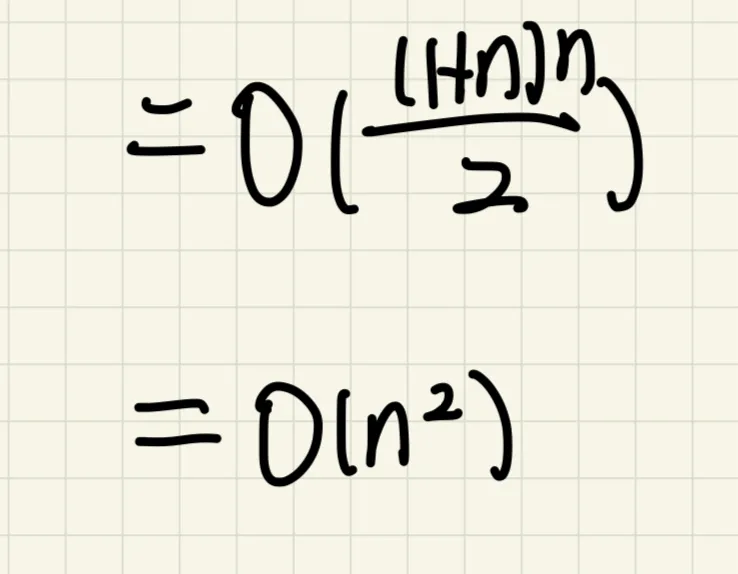
3、题目: 使用分治法的 maxmin 算法寻找数组中的最大值和最小值
实例数组: A=(48,12,61,3,5,19,32,7)
要求:
a.分治过程描述:
描述 maxmin 算法在给定数组 A 上的执行过程。包括初始状态,第1趟状态,直到第n趟(最终)状态。
b.算法分析:
描述分治法的基本原理。分析 maxmin 算法的时间复杂度,包括数学推理和图示说明。
考察知识点:选择问题,选最大与最小
解答:
a.
初始状态:
数组 A={48,12,61,3,5,19,32,7}
第一趟状态:
分割数组为两部分:{48,12,61,3} 和{5,19,32,7}
第二趟状态:
进一步分割每个子数组:
• {48,12}和{61,3}
• {5, 19}和{32,7}
第三趟状态:
处理每个分割后的子数组:
•在{48,12} 中,48是最大值,12是最小值。
•在{61,3}中,61是最大值,3是最小值。
•在{5,19}中,19是最大值,5是最小值。
•在{32,7}中,32是最大值,7是最小值。
第四趟状态(合并结果):
将子数组的结果合并以找出整体的最大值和最小值:
•比较{48,12}的结果和{61,3}的结果得到全局最大值61,最小值3。
•比较{5,19}的结果和{32,7}的结果得到全局最大值32
(这里需要与之前的最大值61比较),最小值5(需要与之前的最小值3比较)。
最终状态:
综合上述结果,最大值为61,最小值为3。
b.
基本原理:
分治法是一种递归算法,它将一个大问题分解为两个或更多的相似的小问题,
这些小问题互相独立且与原问题形式相同。
解决所有小问题后,再将这些小问题的解决结果合并,以产生原问题的解。
maxmin算法的时间复杂度分析:
•每一次递归,都将问题规模减半,即对半分数组。
•对于每一层递归,我们都进行两次递归调用,每次调用处理数组的一半。
•因此,递归的深度为log2(n),其中n是数组的大小。
•在每一层递归中,我们都进行了常数次的比较操作。
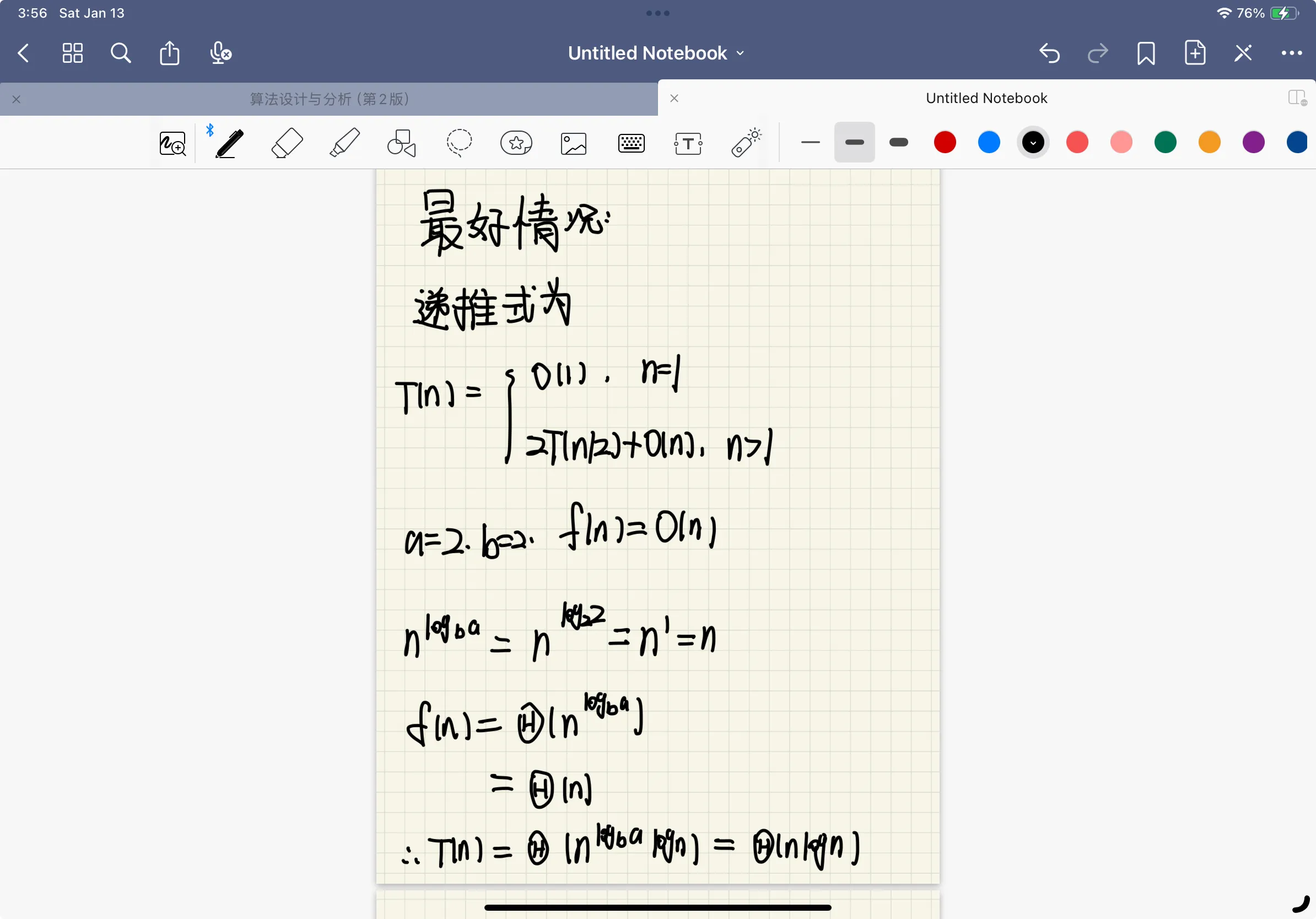
设 T(n)是算法的时间复杂度,则有递推公式:
T(n) = 2T(n/2) + 2
根据主定理,可以解得T(n)=O(n)。
补充:
分治算法的时间复杂度分析:
a(分割因子):这代表在分治算法中每一步递归中产生的子问题的数量。
例如,在二分查找中,我们每次都将问题分成两部分(a=2),而在归并排序中,
每次递归通常也会产生两个子问题(a=2)。
n/b(子问题大小):这里的n是原始问题的大小,而b是一个用于划分每个子问
题的大小的因子。在每一步递归中,原始问题被分割成更小的子问题,
每个子问题的大小大约是原始问题大小的1/b。
例如,在归并排序中,如果我们有n个元素,每个子问题将包含n/2个元素(b=2)。
f(n)(合并成本或额外工作):这表示在分治算法的每个递归步骤中,除了递归
地解决子问题外,还需要进行的额外工作。这可能涉及合并子问题的解决方案,
或者对子问题的结果进行某种形式的处理。
例如,在归并排序中,f(m)代表合并两个已排序的子数组所需的时间,这通常与n成正比。

4、题目: 在电子图书馆的有序书籍目录中应用二分查找
背景场景: 你是一名图书管理员,在电子图书馆管理系统中有一个按书籍编号顺序排列的有序列表。
这个列表包含以下编号:{1,3,9,12,32,41,45,62,75,77,82,95,100}。
你需要快速找到编号为82的书籍。
任务:
1、分治过程描述:
描述使用二分查找法在有序列表中查找编号为82的书籍的过程。
包括初始状态,第1趟状态,直到查找成功(第n趟)的状态。
2、算法分析:
解释二分查找法如何分解问题并逐步缩小查找范围。
分析二分查找的时间复杂度,包括数学推理和图示说明。
要求:计算在查找过程中进行了多少次比较,并描述每一次比较的具体过程。
考察知识点:二分查找
解答:
1.分治过程
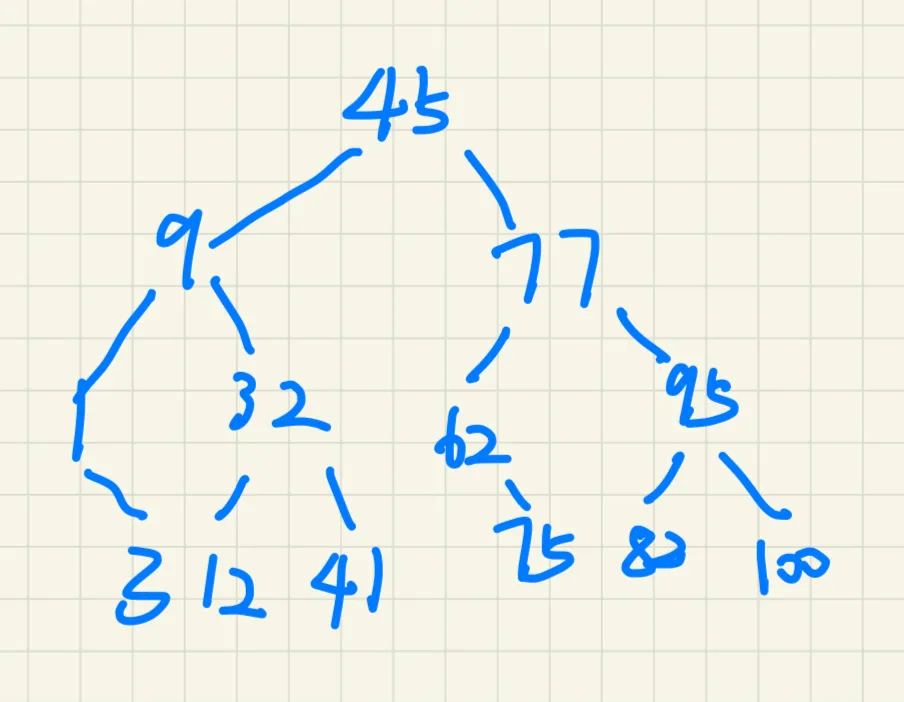
初始状态
• 数组:{1,3,9,12,32,41,45,62,75,77,82,95,100}
• 查找范围:整个数组
• low =0, high = 12(数组索引)
第1趟
• 中间索引:mid =(0+12)/2=6(对应编号45)
• 比较:45<82
• 更新查找范围:右半部分,low=mid+1=7
第2趟
• 中间索引:mid =(7+12)/2=9(对应编号77)
• 比较:77<82
• 更新查找范围:右半部分,low=mid+1=10
第3趟
• 中间索引:mid =(10+12)/2=11(对应编号95)
• 比较:95>82
• 更新查找范围:左半部分,high=mid-1=10
第4趟(查找成功)
• 中间索引:mid =(10+10)/2=10(对应编号82)
• 比较:82==82
• 查找成功:找到编号82的书籍
2.算法分析
如何分解问题
•二分查找通过比较中间元素与目标值来分解问题。
•如果中间元素不是目标值,算法排除一半的元素,只在剩下的一半继续查找。
•这个过程不断重复,每次都将查找范围减半,直到找到目标值或查找范围为空。
时间复杂度分析
•每次比较都将查找范围减半。
•在最坏情况下,算法需要进行log2n次比较,其中n是数组的大小。
•因此,二分查找的时间复杂度是O(logn)。
比较次数
•在本例中,进行了4次比较来找到编号为82的书籍。
•比较的具体过程见第1小问。
图示说明
•每一趟查找都可以视为一次在二叉树的层级上的遍历。
•树的高度决定了最大比较次数,即log2n。
5、考虑一个具体的整数数组,例如:8,3,5,7,6,2,9,1。您的任务是应用分治策略来找出这个数组中的最大元素。
问题要求:
1. 描述分治过程:详细描述上述分治过程中的每一步,包括如何分割和合并子段。
2. 算法分析:分析此分治算法的时间复杂度。使用数学推理或图示方法来说明你的分析。
考虑每个阶段的比较次数,以及总共需要的分割合并次数。
考察知识点:选择问题,选最大
解答:
1.
分解:
首先,将数组分成两个部分。例如,我们可以在中间分割,得到两个子数组:[8,3,5,7]和[6,2,9,1]。
解决:
递归地对每个子数组应用相同的分治策略。
•对于[8,3,5,7],继续分割为[8,3]和[5,7],然后再分别分割,直到每个子数组只有一个元素。
•对于[6,2,9,1],执行相同的分割过程。
合并:
在每个分割级别上,比较子数组的元素,选择最大的元素,然后向上合并。
•比如,在最底层,我们比较单个元素,然后在上一层比较[8]和[3]得到8,比较[5]和[7]得到7,
以此类推,最终得到整个数组的最大元素。
2.
时间复杂度的分析通常基于算法的基本操作次数。
该分治算法的时间复杂度是O(n)。
分析:


6、考虑一个具体的整数数组,例如:8,3,5,7,6,2,9,1。您的任务是应用分治策略来找出这个数组中的第二大元素。
问题要求:
1. 描述分治过程:详细描述上述分治过程中的每一步,包括如何分割和合并子段。
2. 算法分析:分析此分治算法的时间复杂度。使用数学推理或图示方法来说明你的分析。
考虑每个阶段的比较次数,以及总共需要的分割合并次数。
考察知识点:选择问题,选第二大
解答:
1.
分解:
•将数组分成两个部分,例如,数组[8,3,5,7,6,2,9,11]在中间分割成两个子数组
[8,3,5,7]和[6,2,9,1]。
解决:
•递归地对每个子数组应用相同的分治策略,同时寻找子数组中的最大值和第二大值。
合井:
•在每个递归步骤中,比较来自两个子数组的最大值和第二大值,从而确定当前递归层
的最大值和第二大值。
2.
分治过程
•这个函数使用了分治策略。对于一个包含n个元素的数组,每次递归都将问题分成两个子问题,
每个子问题处理一半的元素。
•每一层递归都需要对每个子区间进行比较操作,以确定这个区间的最大值和第二大值。
•因此,分治过程中,每个元素会参与log(n)次比较(因为每次都是将问题规模減半)。
时间复杂度计算
分析:

7、斐波那契数列定义为 F(O)=0, F(1)=1,对于n>1, F(n)= F(n-1)+F(n-2)。
你的任务是编写一个程序,使用分治算法来计算斐波那契数列的第n项,并分析算法的时间复杂度。
1.描述算法的分治过程。
•指出算法的初始状态。
•描述第1趟的状态。
•描述第n趟的状态。
2.编写分治算法。
•描述算法的基本情况。
•描述算法如何递归地分解问题。
3.分析算法的时间复杂度。
•使用数学推理或图示来说明时间复杂度。
•解释为什么时间复杂度是这样的。
考察知识点:斐波那契数列
解答:
1. 描述算法的分治过程。
算法的初始状态
•初始状态是计算斐波那契数列的第n项,其中F(0)=0和F(1)= 1。
第1趟的状态
•在第1趟,如果n大于1,算法将问题分解为计算F(n-1)和F(n-2)。
第n趟的状态
•在第n趟,算法继续分解问题,直到达到基本情况:计算F(O)或F(1)。
2. 编写分治算法。
基本情况
•当n为0时,返回O;当n为1时,返回1。
递归地分解问题
•对于n>1,递归地计算F(n-1)和F(n-2),然后将它们相加以得到F(n)。
代码实现:
#include <stdio.h>
long long fibonacci(int n) {
if (n == 0) return 0;
if (n == 1) return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
int main() {
int n;
printf("请输入要计算的斐波那契数列项数:");
scanf("%d", &n);
long long result = fibonacci(n);
printf("斐波那契数列的第%d项是:%lld\n", n, result);
return 0;
}
3.分析算法的时间复杂度。
数学推理
•斐波那契数列的分治算法对于每个n>1,都进行了两次递归调用。
•这导致递归树的每个节点都分裂成两个子节点,形成一个二叉树的结构。
图示
•可以用一棵二叉树来表示这种递归,其中每个节点有两个子节点(除了叶子节点)。
树的深度为n。
时间复杂度解释
•在这种情况下,时间复杂度可以近似为二叉树的节点总数,即O(2^n)。
•这是因为每增加一个n,递归树的大小几乎翻倍。
总结
•因此,该分治算法的时间复杂度是指数级的,即O(2^n)。这是一个效率非常低的算法,特别是对于较大的n值。
8、假设有三根柱子 A、B和C。开始时,A柱子上有n个逐渐增大的盘子,目标是将这些盘子全部移动到C柱子上,
遵循以下规则:每次只能移动一个盘子,且在移动过程中,大盘子不能放在小盘子上面。
小问分解:
1. 问题一:描述初始状态下,盘子的排列和目标。
2. 问题二:描述第一次移动后,三根柱子上盘子的状态。
3. 问题三:若n=3,详细描述整个移动过程的每一步。
4. 问题四:使用分治策略描述算法的步骤。
5. 问题五:分析此算法的时间复杂度,并解释为什么时间复杂度是这样的。
考察知识点:汉诺塔问题
问题一:初始状态和目标
初始状态
•开始时,所有盘子按照大小顺序排列在A柱上,最大的盘子在底部,最小的盘子在顶部。
目标
•将所有盘子移动到C柱上,移动过程中必须遵循同样的规则:任何时候大盘子不能放在小盘子上面。
问题二:第一次移动后的状态
•第一次移动通常是将最小的盘子(顶部的盘子)从A柱移动到C柱(如果盘子总数是奇数)
或B柱(如果盘子总数是偶数)。
•因此,此时A柱上会有剩下的盘子,B柱或C柱上会有一个最小的盘子。
问题三:n=3的移动过程
1.将最小的盘子从A移到C。
2.将次小的盘子从A移到B。
3.将最小的盘子从C移到B。
4.将最大的盘子从A移到C。
5.将最小的盘子从B移到A。
6.将次小的盘子从B移到C。
7.将最小的盘子从A移到C。
问题四:分治策略描述
分治策略涉及将问题分解为更小的、更易于管理的问题,然后将这些问题的解决方案合并以解決原始问题。
1.分解:将问题分解为移动最上面的n-1个盘子到辅助柱(B柱),然后移动最底部的大盘子到目标柱(C柱)。
2.解决:递归地移动这n-1个盘子。
3.合并:将n-1个盘子从辅助柱移动到目标柱(C柱),在此过程中,初始柱(A柱)作为辅助柱。
问题五:时间复杂度分析
•移动n个盘子的步骤数是指数性增长的。每增加一个盘子,所需的步骤数都会翻倍并加一。
•对于n个盘子,总步骤数 T(n)=2*T(n-1)+1。
•因此,算法的时间复杂度是0(2^n)。

9、归并排序
请用分治策略设计递归的归并排序算法,并分析其时间复杂性(要求:分别
给出 divide、conquer、combine 这三个阶段所花的时间,并在此基础上列出递归
方程,最后用套用公式法求出其解的渐进阶)
解答:
a.三个阶段所花的时间:
1. Divide(分):将数组分成两个子数组,每个子数组大约是原数组的一半大小。
这个步骤的时间复杂度是 O(1),因为它只涉及计算中点。
2. Conquer(治):递归地对这两个子数组进行归并排序。当子数组大小减少到1或0时,递归结束。
由于每次递归都会将数组分成一半,所以总共会有logn层递归。
3. Combine(合):将两个已排序的子数组合并成一个有序的数组。
合并两个大小为n/2的数组的时间复杂度是O(n)。
递归方程为:
T (n) = 2T (n/2) + O(n)
设T(n)是对大小为n的数组进行归并排序所需的时间。那么根据上述分析,递归方
这里,2T(n/2)是两次递归调用处理两个子数组的时间,O(n)是合并时间。
时间复杂性分析:
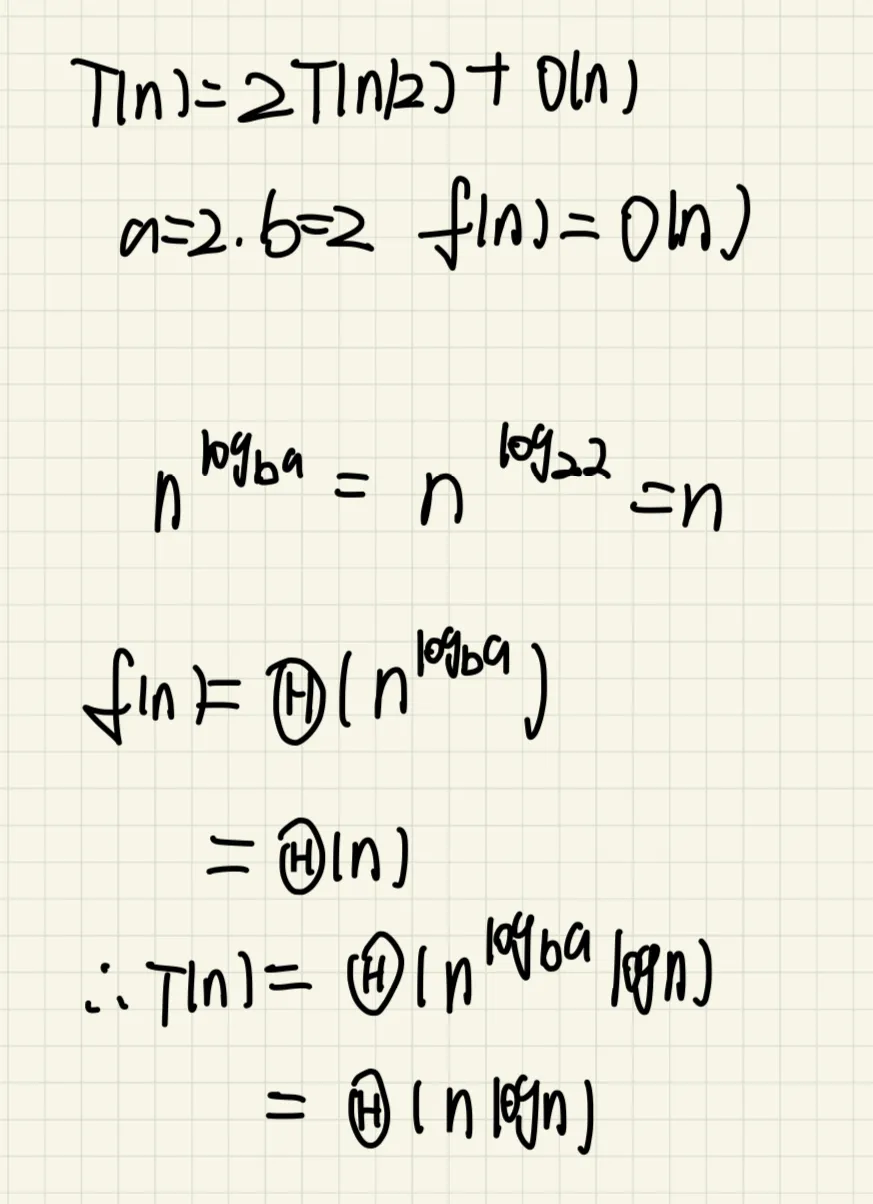
这表明归并排序在所有情况下的时间复杂度都是 O(nlogn)。
10、

解答:
(1)
基本思路是将数组分成两部分,递归地在每部分中找到最小元素和第二小元素,
然后将这两部分的结果合并以得到整个数组的最小元素和第二小元素。
•分解:将数组 A[1...n]分为两个大小相等的子数组 A[1...n/2]和 A[n/2+1...n]。
•递归求解:分别在这两个子数组中递归地找到最小元素和第二小元素。
这将给我们两对元素(每对包含一个最小元素和一个第二小元素)。
•合并:比较这两对元素,找到整个数组的最小元素和第二小元素。
合并步骤的关键在于,我们首先比较两个最小元素以确定整个数组的最小元素。
然后,我们只需要比较三个元素来确定第二小元素:两个子数组中的第二小元素和较大的最小元素。
(2)
递归方程:
对于大小为n的数组,比较次数 T(n)可以表达为:
T(n) = 2T (n/2) + 3
其中,2T(n/2)是在两个子数组上找到最小元素和第二小元素的比较次数,
3是在合并步骤中确定整个数组的最小元素和第二小元素的额外比较次数。
证明略。