贪心算法大题
0、考察重点
题3,第四章贪心
关键词
1、思路,构造局部最优的策略
2、时间复杂度(关键步骤在哪里)
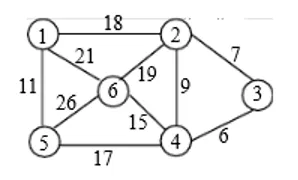
1、对下图所示的连通网络G,用克鲁斯卡尔(Kruskal)/Prim算法求G的最小生成树T,
请写出在算法执行过程中,依次加入T的边集TE中的边。说明该算法的贪心策略和算法的基本思想,
并简要分析算法的时间复杂度。
解答:
a.
使用克鲁斯卡尔算法对提供的图G求最小生成树T的过程如下:
1. 首先,我们将所有边按照权重从小到大排序。
2. 然后,逐一考虑每条边,确保加入的边不会与已选的边集TE形成环。
3. 不断重复上述过程,直到形成最小生成树T。
按照这个过程,依次加入到最小生成树T的边集TE中的边为:
(4, 3, 6)
(2, 3, 7)
(1, 5, 11)
(6, 4, 15)
(5, 4, 17)
这些边依次被加入到最小生成树中,形成最终的最小生成树。
算法的贪心策略:
克鲁斯卡尔算法的贪心策略在于每次选择连接两个不同子集的最小边,这保证了每次
加入到生成树T中的边都是当前可用边中最小的,从而确保最终形成的生成树的总权重尽可能小。
算法的基本思想:
算法的基本思想是通过局部最优选择(每次选择最小的边)来达到全局最优解(最小生成树的最小总权重)。
或者
将所有边按权值升序排列,依次选边,只要不构成回路就选,直到n-1条边。
时间复杂度分析:
克鲁斯卡尔算法的时间复杂度主要由排序和查找最小边的操作决定。排序的时间复杂度是O(ElogE),
其中E是边的数量。查找和合并操作可以通过优化后的并查集操作进行,时间复杂度接近O(1),
因此整体算法的时间复杂度是O(ElogE)。
b.
使用Prim算法对提供的图G求最小生成树T的过程如下:
初始化:选择一个顶点作为起始点,并将其标记为已访问。初始化一个记录最小权重的数组,
初始时除了起始顶点外,所有顶点的权重设置为无穷大。
选择边并更新权重:从所有未访问的顶点中,选择一条权重最小且连接到已访问顶点的边。
将这条边及其连接的顶点加入到最小生成树中,并更新未访问顶点到已访问顶点集的最小权重。
构建最小生成树:重复步骤2,直到所有顶点都被访问。每次迭代选择一条新边加入到最小生成树中,
直到连接所有顶点。
按照Prim算法的过程,依次加入到最小生成树T的边集TE中的边为:
(1, 5, 11)
(5, 4, 17)
(4, 3, 6)
(3, 2, 7)
(4, 6, 15)
这些边按照它们被加入到最小生成树中的顺序列出。
算法的贪心策略:
Prim算法的贪心策略在于每次选择当前可用的最小的边加入到生成树中,
确保每次加入的边都能使得生成树的权重增长最小。
时间复杂度分析:
Prim算法会从一个顶点开始,然后在每一步选择一个与当前最小生成树边权最小的边来扩展这棵树。
在使用数组的情况下,每次找到这样一条边需要遍历所有的边,因此每次操作的复杂度是O(V)。
由于算法需要选择V-1条边来形成最小生成树(一个有V个顶点的图的最小生成树有V-1条边),
所以总的时间复杂度是O(V^2)。
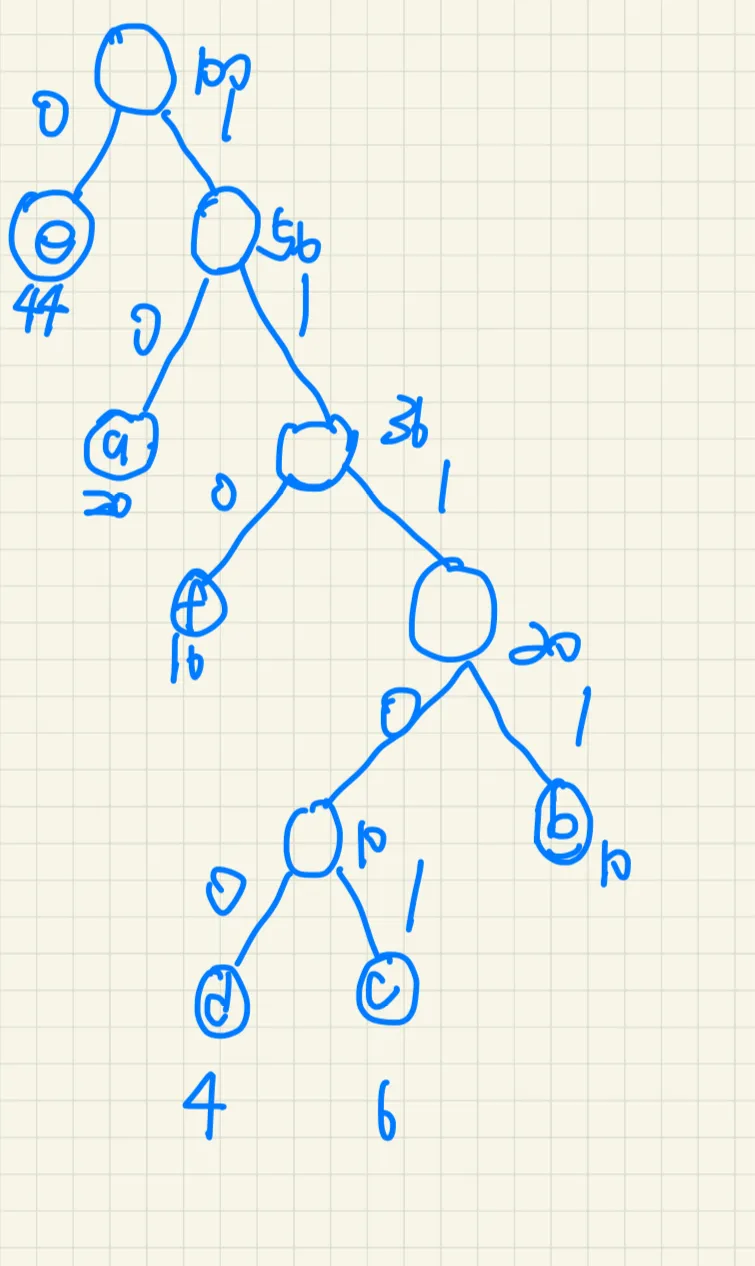
2、考虑用哈夫曼算法来找字符a,b,c,d,e,f 的最优编码。
这些字符出现在文件中的频数之比为20:10:6:4:44:16。要求:
(1)简述使用哈夫曼算法构造最优编码的基本步骤;
(2)构造对应的哈夫曼树,并据此给出a,b,c,d,e,f 的一种最优编码。
(3)分析时间复杂度
解答:
(1)
基本步骤:
1. 初始化森林
每个字符都对应一棵仅包含单个结点的树,这个结点是树的根,其权值(根权)是该字符在文件中的频率。
这些单结点树构成了一个森林。
2. 合并过程
在接下来的每一步中,都会在森林中选取根权最小的两棵树。这两棵树被合并成一棵新树,新树的根结点
是两个原始根结点的父节点。新根的权值是两个子树根权之和。
3. 重复合井
这个合并过程会重复进行,每次都减少森林中树的数量,直到最后只剩下一棵树。这棵最终的树就是哈夫曼树。
4. 编码生成
在最终的哈夫曼树中,每个原始字符对应的结点到根结点的路径定义了该字符的编码。一般约定向左的路径
表示“O”,向右的路径表示“中”。
通过这个方法,哈夫曼算法确保了频率较高的字符有较短的编码,而频率较低的字符有较长的编码,
从而实现了数据的有效压缩。
(2)
构造的哈夫曼树编码:
a:10
b:1111
c:11101
d:11100
e:0
f:110
3、时间复杂度为O(nlogn)
3、通过键盘输入一个高精度的正整数n(n的有效位数≤240),去掉其中任意s个数字后,
剩下的数字按原左右次序将组成一个新的正整数。对给定的n和s,
寻找一个方案,使得剩下的数字组成新的最小的正整数。
如输入n为178543,s为4,结果为13
试用贪心法解决此问题,请:
(1) 给出用贪心法求解该最优化问题的贪心选择策略。
(2) 请补全下列贪心算法求出对正整数n去掉s个数字之后得到的新的最小的正整数。
(3) 此算法的渐进时间复杂度?
解答:
1、
贪心算法在每一步选择中都采取在当前看来最好的选择,希望通过局部最优的选择来达到全局最优的结果。
在这个问题中,我们的目标是在去除s个数字后得到一个尽可能小的新整数。因此,贪心策略如下:
从左到右遍历数字n,每次找到一个数字,如果这个数字大于其后面的数字,就将其删除。
这样做的理由是,删除较大的数字能更快地减小整体值。
重复这个过程,直到删除了s个数字或者没有更多可以删除的数字(因为剩余的数字是升序排列的)。
2、略。
3、
关于算法的时间复杂度,我们需要考虑两个主要因素:数字n的长度和我们需要删除的数字数量S。
最坏情况下,算法可能需要遍历整个数字n以找到要删除的数字,这需要O(n)时间,
其中n是数字的长度。因为这个过程最多重复s次,所以总的时间复杂度是O(n*s).
综上所述,这个贪心算法的渐进时间复杂度是O(n*s)。
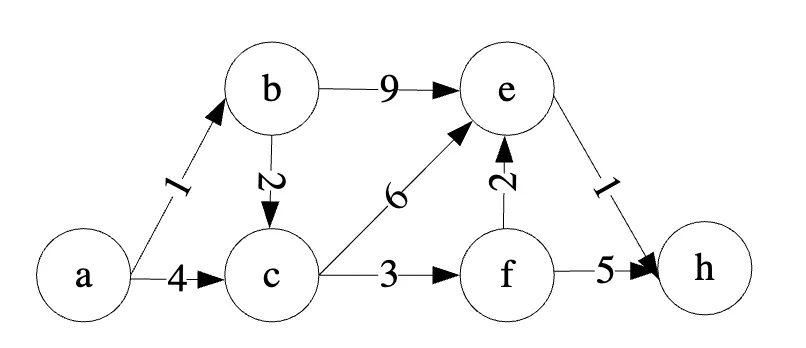
4、请写出 Dijkstra 算法的具体计算步骤,并根据代码求从定点a到其它所有顶点的最短距离。
并分析该算法的时间复杂度
解答:
Dijkstra算法是一种用于在加权图中找到最短路径的算法。它从源节点开始,逐渐扩展到图中的所有节点,
为每个节点维护当前找到的从源节点到该节点的最短路径。具体的计算步骤如下:
1. 创建两个集合:已确定最短路径的节点集合(S)和未确定最短路径的节点集合(Q)。
2. 将所有节点的最短路径估计值初始化为无穷大,源节点的最短路径值初始化为0。
3. 将所有节点放入集合Q中。
4. 当集合Q非空时:
a. 从Q中选择一个距离最小的节点u(初始时为源节点)。
b.将u从Q中移除并放入S中。
c.对于每个从u出发的边(u,v),如果v在Q中,则更新v的最短路径值:
如果通过u到v的路径比当前记录的路径更短,则更新它。
重复这个过程,直到集合Q为空。集合S中的每个节点的最短路径值就是从源节点到该节点的最短路径长度。
根据Dijkstra算法计算的结果,从顶点a到其它所有顶点的最短距离如下:
• a到a的最短距离是O(因为它是起点)
• a到b的最短距离是2
• a到c的最短距离是3
• a到e的最短距离是9
• a到f的最短距离是6
• a到h的最短距离是10
在这种实现中,我们在每一步都需要O(n)的时间来找到未处理的最小距离顶点,
并且我们需要进行n次这样的步骤(因为每个顶点都需要被处理一次)。因此,总时间复杂度是O(n^2).
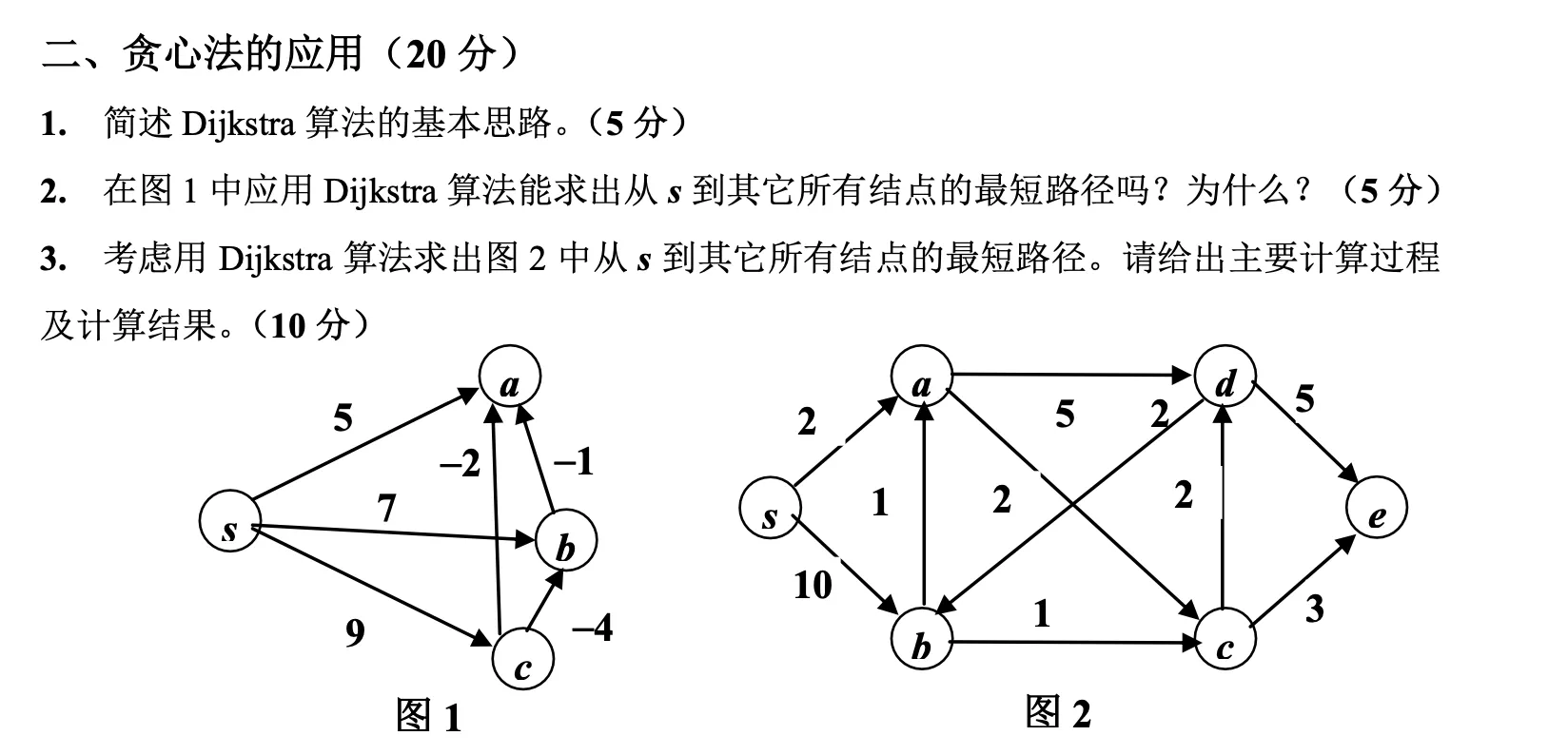
5、
解答:
1.基本思路
Dijkstra算法是一种用于在加权图中找到从单个源到所有其他节点的最短路径的算法。基本思路是这样的:
初始化:将所有节点标记为未访问,给每个节点一个距离值,源节点为0,所有其他节点为无限大。
对所有未访问节点,选择距离最小的节点,称为当前节点。
更新当前节点所有未访问的邻居的距离值:如果通过当前节点到邻居节点的距离小于已知的距离,则更新该距离。
当前节点标记为已访问。
重复上述步骤直到所有节点都被访问。
2.
在图1中,我们看到有向图中有些边的权值是负数。如我之前所述,Dijkstra算法不能正确处理带有负权边的图。在Dijkstra算法中,一旦一个节点的最短路径被确定,该节点就会被标记为已访问,并且其最短路径长度不会被后续的操作改变。但是,在存在负权边的情况下,一个节点的最短路径可能会因为之后的计算而变短,这违反了Dijkstra算法的基本假设。
具体来说,如果你先访问了节点s到节点a的路径(假设其权值为正数),然后访问了节点a到节点b的路径,如果a到b的路径权值为负数,并且其绝对值足够大,那么这会导致从s到b的总路径长度减少。这意味着在算法执行过程中,之前确定的最短路径可能不再是最短的。
因此,在图1这样含有负权边的图中,我们不能使用Dijkstra算法来找到从源节点s到其它所有节点的最短路径。需要使用其他算法,如Bellman-Ford算法,它能够处理负权边并且能够在图中存在负权环时报告无解。
3.计算过程、计算结果
